This post goes over the RustPython parser. You can see the source code in the rustpython-parser crate.
When you write code in Python and run it, an interpreter, such as the RustPython interpreter, acts as the translator between you and your machine.
The interpreter has the job of turning your human code into bytecode that a Python virtual machine can run. Bytecode is an intermediate code between source code and machine code. This makes it portable across multiple hardware and operating systems. Bytecode “works” as long as you implement a virtual machine (vm) that can run it. There is a performance penalty for this flexibility. RustPython also has a vm that interprets the generated bytecode, other posts will go into the details of that vm but now let’s figure out how to turn code into bytecode.
What bytecode looks like
Seeing is believing. To see what bytecode looks like, you can use a Python module called dis. “dis” is short of for _dis_assembler. You can write source code then see how its bytecode looks like. Here is an example:
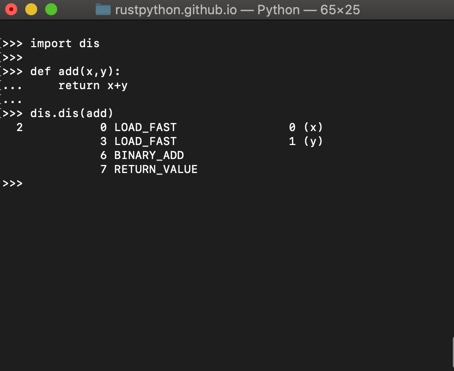
How RustPython turns your code into bytecode
Here are the main steps that RustPython currently goes through:
- parse the line of source code into tokens
- determine if the tokens have a valid syntax
- create an Abstract Syntax Tree (AST)
- compile the AST into bytecode
This list of steps introduces some new concepts like: tokens and abstract syntax trees. We’ll explain and demistify those.
Step 1: parsing source code into tokens
The fastest way to understand what tokens are, is to see them. Conveniently, Python comes with a tokenizer. Here is what happens if I run the tokenizer on the function that I created above.
$ python -m tokenize file.py
file.py has the function that I used in the previous example.
def add(x,y):
return x+y
Tokenize output:
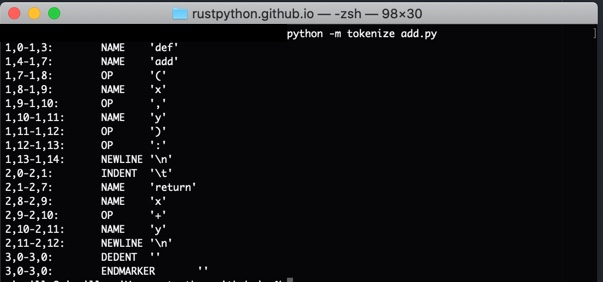
A picture IS worth a thousand words 😛 Those are the tokens. They are the basic “units” of the programming language. They are the keywords and operators that you typed. Even new lines and identation count.
If you want to sound fancy:
- The tokens are the basic “lexical components”
- The parsing process is called “lexical analysis”
- The thing that does this is a “lexer”
The code for the lexing stage lives in lex.rs of the parser crate.
If you want to dive into the details of lexical analysis, check out Python in a nutshell / Lexical structure
Step 2 : determine if the tokens are valid syntax
In the previous step, if you add random stuff to your function and tokenize it, it will work and still tokenize.
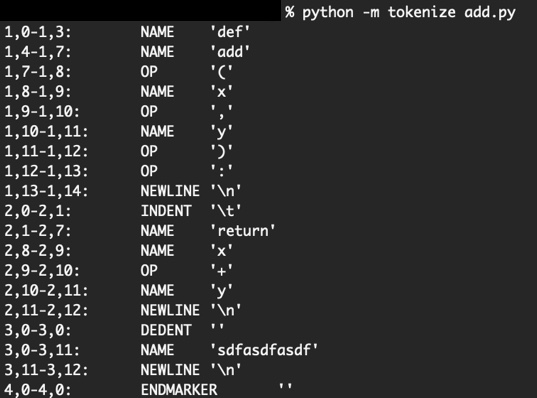
So don’t hate on the whole interpreter when you get error messages! or at least don’t hate on the tokenizer!
To determine if the tokens are valid syntax, first you need a definition of what a valid syntax is. Python has a defined “grammar” or set of rules. The official reference is on this link. There, you will find a machine readable file. You may read a book to know the rules of Python, but words are too “fluffy”, an algorithm that verifies if the rules are followed needs a very strict set of rules encoded in a file. This video explains the Python grammar and the file’s notation. As the presenter puts it, this is the spirit of the beast (Python) and it is only ~10KB 😭 (compare that to the size of the Python books you had to read!)
So, we have the rules or grammar of a programming language in a machine encoded format… now we need to write something that verifies that those rules were followed… This sounds like something that other people could use and like something that should exist as an open source project! 🤔
Sure enough, there is a whole Rust framework called LALRPOP. It takes the tokens generated by the lexer, verifies the syntax and turns the tokens into an AST (Abstract Syntax Tree). More information and a tutorial can be found in the LALRPOP book.
RustPython does one nice extra thing on top of LALRPOP. It masks the errors and provides you with safer, nicer errors. You can see the code for this in RustPython/parser/src/error.rs
Using RustPython to generate an AST
You can do:
use rustpython_parser::{parser, ast};
let python_source = "print('Hello world')";
let python_ast = parser::parse_expression(python_source).unwrap();
Recap 🥴 🥵
As a recap, when you write a line of Python code and “run it”, here is what the RustPython interpreter does:
INPUT: your code (in file.py or interactive shell)
⬇️ parse the line of source code into tokens
⬇️ determine if the tokens are valid syntax
⬇️ create an Abstract Syntax Tree (AST)
⬇️ compile the AST into bytecode
OUTPUT: bytecode (in __pycache__/file.pyc or in memory)
The compiler is located in the rustpython-compiler crate. Keep an eye on the blog for a future post about the details or the compiler. In the meantime, check out the parser source code in rustpython-parser.